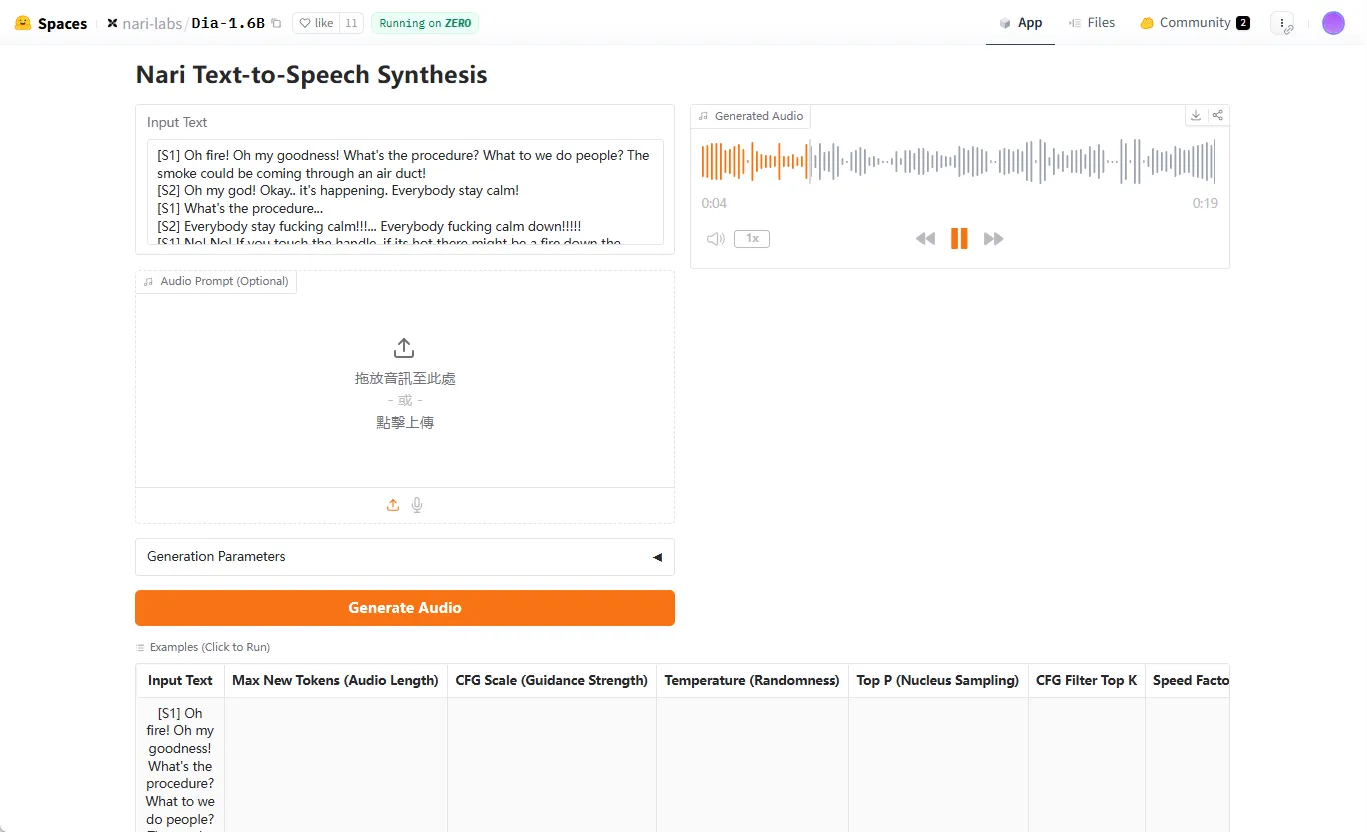
KittenTTS
综合介绍
KittenTTS 是一个开源的文本转语音(TTS)模型,由 KittenML 开发。 其最主要的特点是模型文件极小,预览版的参数量仅为1500万,大小低于25MB。 这样的设计让它专注于在计算资源有限的设备上高效运行,例如普通的个人电脑、智能手机甚至是树莓派(Raspberry Pi)等嵌入式设备。 该模型经过了CPU优化,无需依赖GPU即可进行快速的语音合成,从而实现实时或近实时的音频生成。 KittenTTS 目前提供8种不同的英文语音(4种男声和4种女声),并且计划在未来支持更多语言。 该项目以Apache-2.0许可证开源,用户可以免费使用。
功能列表
- 超轻量级: 模型文件大小低于25MB,参数量仅1500万,便于在各种设备上部署。
- CPU优化: 无需GPU硬件加速,即可在普通CPU设备上流畅运行。
- 快速推理: 经过优化,能够实现快速的实时语音合成。
- 多种声音选择: 提供8种不同的预设声音,包括4种男声和4种女声。
- 开源免费: 项目基于Apache-2.0许可证,代码和模型权重完全开放,可免费用于商业或个人项目。
- 易于使用: 提供简单的Python代码示例,只需几行代码即可完成文本到语音的转换。
- 跨平台兼容: 设计目标是“能在任何地方运行”,兼容包括个人电脑、手机和树莓派等多种硬件平台。
使用帮助
KittenTTS 的设计目标是简单易用,开发者可以很轻松地将其集成到自己的Python项目中。以下是详细的安装和使用流程。
安装
KittenTTS 目前通过一个.whl包文件进行分发,可以直接使用Python的包管理工具pip从GitHub的发布页面进行安装。
打开你的终端或命令行工具,输入以下命令:
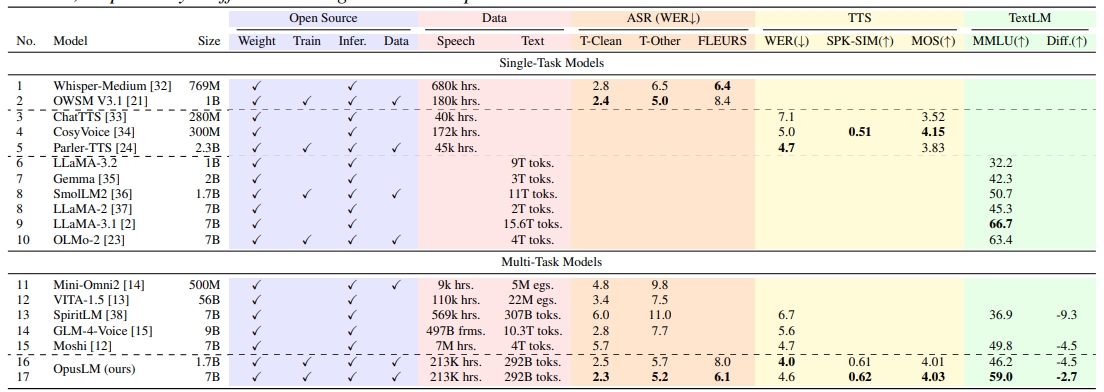
pip install https://github.com/KittenML/KittenTTS/releases/download/0.1/kittentts-0.1.0-py3-none-any.whl
这个命令会自动下载并安装KittenTTS及其所需的依赖库。安装过程很快,因为它不包含庞大的模型文件。模型文件会在首次使用时自动从Hugging Face下载。
基本操作流程
安装完成后,你就可以在Python代码中调用KittenTTS来生成语音了。整个过程可以分为三步:导入模块、加载模型、生成音频。
- 导入 KittenTTS 类首先,你需要从
kittentts库中导入核心的KittenTTS类。from kittentts import KittenTTS - 加载模型接下来,创建
KittenTTS类的一个实例。在创建实例时,你需要指定要加载的模型。KittenTTS的默认模型托管在Hugging Face上,名称为KittenML/kitten-tts-nano-0.1。# 创建模型实例,程序会自动从Hugging Face下载并加载模型 m = KittenTTS("KittenML/kitten-tts-nano-0.1") ``` 当你第一次运行这行代码时,程序会检查本地缓存。如果找不到模型文件,它会自动从网上下载,这个过程可能需要一些时间,具体取决于你的网络状况。下载完成后,模型会保存在本地,后续加载会非常快。 - 生成音频并选择声音加载模型后,调用实例的
generate方法即可将文本转换为音频。这个方法接受两个核心参数:text: 你想要转换为语音的文本字符串。voice(可选): 用于指定生成语音的声音。
KittenTTS(nano-0.1版本)目前提供了8种内置的声音供用户选择:
- 男声:
expr-voice-2-m,expr-voice-3-m,expr-voice-4-m,expr-voice-5-m - 女声:
expr-voice-2-f,expr-voice-3-f,expr-voice-4-f,expr-voice-5-f
以下是一个完整的示例,演示如何生成一段语音并选择一个特定的声音:
# 要转换的文本 text_to_speak = "这个高质量的文本转语音模型不需要GPU就可以运行。" # 调用generate方法,并选择'expr-voice-2-f'(女声) audio_data = m.generate(text_to_speak, voice='expr-voice-2-f')generate方法会返回一个NumPy数组,其中包含了生成的音频波形数据。 - 保存音频文件最后一步是将生成的音频数据保存为常见的音频文件格式,例如
.wav。这需要借助一个第三方库soundfile。KittenTTS的requirements.txt中包含了这个库,因此在安装时已经自动安装好了。import soundfile as sf # 将音频数据写入名为'output.wav'的文件 # KittenTTS生成的音频采样率为24000Hz sf.write('output.wav', audio_data, 24000)运行完这段代码后,你会在当前目录下找到一个名为
output.wav的文件,播放它就可以听到生成的语音了。
完整代码示例
将以上步骤整合在一起,就得到了一个可以独立运行的完整脚本:
# 1. 导入所需模块
from kittentts import KittenTTS
import soundfile as sf
# 2. 加载TTS模型
# 模型名称 "KittenML/kitten-tts-nano-0.1"
m = KittenTTS("KittenML/kitten-tts-nano-0.1")
# 3. 定义要转换的文本和选择的声音
text_to_speak = "你好,欢迎使用KittenTTS。这是一个轻量级的文本转语音模型。"
# 可用的声音列表: [ 'expr-voice-2-m', 'expr-voice-2-f', 'expr-voice-3-m', 'expr-voice-3-f', 'expr-voice-4-m', 'expr-voice-4-f', 'expr-voice-5-m', 'expr-voice-5-f' ]
selected_voice = 'expr-voice-4-f'
# 4. 生成音频数据
print(f"正在使用声音 '{selected_voice}' 生成语音...")
audio_data = m.generate(text_to_speak, voice=selected_voice)
print("语音生成完毕!")
# 5. 保存为WAV文件
output_filename = 'hello_kittentts.wav'
sf.write(output_filename, audio_data, 24000) # 采样率为 24000
print(f"音频文件已保存为: {output_filename}")
这个脚本展示了从加载模型到最终保存文件的完整流程,用户可以直接复制并运行此代码来体验KittenTTS的功能。
应用场景
- 智能家居与物联网设备在计算能力有限的智能音箱、智能家居中控或物联网(IoT)设备上,KittenTTS可以作为离线的语音播报模块。 由于它不依赖云端服务和GPU,因此可以实现低延迟的本地响应,例如播报天气、提醒事项或设备状态,同时保护用户隐私。
- 个人语音助手开发者可以利用KittenTTS为个人电脑或树莓派等硬件DIY一个本地运行的语音助手。 结合语音识别技术,它可以接收指令并用自然的语音进行反馈,整个过程完全在本地完成,无需网络连接。
- 辅助阅读工具可以开发轻量级的桌面应用或浏览器插件,将网页内容或电子书文本转换为语音,为视力障碍者或希望在处理其他事务时“听”内容的用户提供帮助。其小巧的体积使其非常适合嵌入到资源有限的应用程序中。
- 游戏开发在独立游戏或资源受限的游戏项目中,KittenTTS可用于生成角色的对话语音。 虽然语音质量可能不如大型商业TTS系统,但其极低的资源占用和快速的生成速度使其成为一个有吸引力的选择,尤其适合为非关键NPC或系统提示音提供配音。
QA
- KittenTTS支持中文吗?目前(nano-0.1版本)仅支持英文。 但是,根据项目的介绍,未来计划支持多语言,中文可能在未来的更新中被加入。
- 生成的语音质量如何?作为一个参数量仅1500万的超轻量级模型,其语音质量在清晰度和自然度上表现尚可,能够满足基本的语音播报和提示需求。 与动辄上百兆甚至数G的大型TTS模型相比,音质不是其主要优势,但对于其极小的体积来说,效果是相当不错的。
- 我可以在商业项目中使用KittenTTS吗?可以。KittenTTS采用Apache-2.0许可证,这是一个非常宽松的开源许可协议,允许用户在个人和商业项目中使用、修改和分发,只需在项目中保留原始的版权和许可声明即可。
- 运行KittenTTS需要什么样的电脑配置?几乎任何现代电脑都可以运行KittenTTS。 它为CPU进行了专门优化,不需要GPU,内存占用也很低,甚至可以在树莓派这样的单板计算机上流畅运行,因此硬件门槛非常低。